
MySQL TODO LO QUE QUERIAS SAVER

Ire recopilando información y ampliandola en este blog, si teneis alguna duda podeis preguntar o dejar un comentario, ya que yo estoy empezando a aprender MySQL, intentare poner toda la información que valla recopilando o que me vallais sugiriendo.
¿Qué es MySQL?
Primero lo primero, tienes que saber cómo pronunciarlo: MY-ES-KYU-EL’ [maɪˌɛsˌkjuːˈɛl]. Una compañía sueca llamada MySQL AB originalmente desarrolló MySQL en 1994. La compañía de tecnología de los Estados Unidos Sun Microsystems luego tomó el control por completo cuando compró MySQL AB en el 2008. El gigante de la tecnología estadounidense Oracle adquirió Sun Microsystems en el 2010, y MySQL ha sido propiedad de Oracle desde entonces.
¿ Que es una base de datos?
Una base de datos es simplemente una colección de datos estructurados. Imagina que te tomas una selfie: presionas un botón y capturas una imagen de ti mismo. Tu foto es información y la galería de tu teléfono es la base de datos. Una base de datos es un lugar en el que los datos son almacenados y organizados. La palabra «relacional» significa que los datos almacenados en el conjunto de datos son organizados en forma de tablas. Cada tabla se relaciona de alguna manera. Si el software no es compatible con el modelo de datos relacionales, simplemente se llama DBMS.
En cuanto a la definición general, MySQL es un sistema de gestión de bases de datos relacionales de código abierto (RDBMS, por sus siglas en inglés) con un modelo cliente-servidor. RDBMS es un software o servicio utilizado para crear y administrar bases de datos basadas en un modelo relacional.
¿ Que es código abierto?
Código abierto significa que eres libre de usarlo y modificarlo. Cualquiera puede instalar el software. También puedes aprender y personalizar el código fuente para que se adapte mejor a tus necesidades. Sin embargo, la GPL (licencia pública de GNU) determina lo que puedes hacer según las condiciones. La versión con licencia comercial está disponible si necesitas una propiedad más flexible y un soporte avanzado.
¿Que significa modelo cliente-servidor?
Las computadoras que tienen instalado y ejecutan el software RDBMS se llaman clientes. Siempre que necesitan acceder a los datos, se conectan al servidor RDBMS. Esa es la parte «cliente-servidor».
MySQL es una de las muchas opciones de software RDBMS. Suele pensarse que RDBMS y MySQL son lo mismo debido a la popularidad de MySQL. Para nombrar algunas aplicaciones web grandes como Facebook, Twitter, YouTube, Google y Yahoo!, todas usan MySQL para el almacenamiento de datos. Aunque inicialmente se creó para un uso limitado, ahora es compatible con muchas plataformas de computación importantes como Linux, macOS, Microsoft Windows y Ubuntu.
Significado de SQL
MySQL y SQL no son lo mismo. Ten en cuenta que MySQL es una de las marcas más populares de software RDBMS, que implementa un modelo cliente-servidor. Entonces, ¿cómo se comunican el cliente y el servidor en un entorno RDBMS? Utilizan un lenguaje específico del dominio: lenguaje de consulta estructurado (SQL, Structured Query Language). Cuando veas otros nombres que contienen SQL, como PostgreSQL y el servidor Microsoft SQL, es muy probable que sean marcas que también utilizan la sintaxis SQL. El software RDBMS a menudo se escribe en otros lenguajes de programación, pero siempre usa SQL como lenguaje principal para interactuar con la base de datos. MySQL como tal está escrito en C y C ++. Pasa como con los países sudamericanos, todos son geográficamente diferentes y tienen historias diferentes, pero todos hablan principalmente español.
El científico informático Ted Codd desarrolló SQL a principios de la década de 1970 con un modelo relacional basado en IBM. Se volvió más común en 1974 y reemplazó rápidamente a lenguajes similares, por entonces obsoletos, ISAM y VISAM.
Dejando de lado la historia, SQL le dice al servidor qué hacer con los datos. Es similar a tu contraseña o código de WordPress. Lo ingresas en el sistema para obtener acceso al área del panel de control. En este caso, las declaraciones de SQL pueden indicarle al servidor que realice ciertas operaciones:
- Consulta de datos: solicitar información específica de la base de datos existente.
- Manipulación de datos: agregar, eliminar, cambiar, ordenar y otras operaciones para modificar los datos, los valores o los elementos visuales.
- Identidad de datos: definir tipos de datos, por ejemplo, cambiar datos numéricos a números enteros. Esto también incluye la definición de un esquema o la relación de cada tabla en la base de datos.
- Control de acceso a los datos: proporcionar técnicas de seguridad para proteger los datos, lo que incluye decidir quién puede ver o usar cualquier información almacenada en la base de datos.
¿Cómo funciona MySQL?
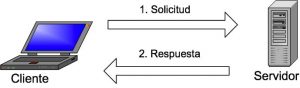
La imagen explica la estructura básica cliente-servidor. Uno o más dispositivos (clientes) se conectan a un servidor a través de una red específica. Cada cliente puede realizar una solicitud desde la interfaz gráfica de usuario (GUI) en sus pantallas, y el servidor producirá el output deseado, siempre que ambas partes entiendan la instrucción. Sin meternos demasiado a fondo en temas técnicos, los procesos principales que tienen lugar en un entorno MySQL son los mismos, y son:
- MySQL crea una base de datos para almacenar y manipular datos, definiendo la relación de cada tabla.
- Los clientes pueden realizar solicitudes escribiendo instrucciones SQL específicas en MySQL.
- La aplicación del servidor responderá con la información solicitada y esta aparecerá frente a los clientes.
Y eso es prácticamente todo. Desde el lado de los clientes, generalmente enfatizan qué GUI de MySQL usar. Cuanto más ligera y fácil de usar sea la GUI, más rápidas y fáciles serán sus actividades de administración de datos. Algunas de las GUI de MySQL más populares son MySQL WorkBench, SequelPro, DBVisualizer y Navicat DB Admin Tool. Algunas de ellas son gratuitas, mientras que otras son comerciales, otras son exclusivamente para macOS y otras son compatibles con los principales sistemas operativos. Los clientes deben elegir la GUI en función de sus necesidades. Para la administración de bases de datos web, incluido un sitio de WordPress, la opción más obvia es phpMyAdmin.
¿Por qué MySQL es tan popular?
¿El por que es tan popular MySQL?
Flexible y fácil de usar
Puedes modificar el código fuente para satisfacer tus propias expectativas, y no tienes que pagar nada por este nivel de libertad, incluidas las opciones de actualización a la versión comercial avanzada. El proceso de instalación es relativamente simple y no debería durar más de 30 minutos.
Alto rendimiento
Un amplio compendio de servidores de clúster respalda a MySQL. Ya sea que estés almacenando enormes cantidades de datos de e-Commerce grandes o realizando actividades intensas de inteligencia de negocios, MySQL puede ayudarte sin problemas con una velocidad óptima.
Un estándar de la industria
Las industrias han estado usando MySQL durante años, lo que significa que hay abundantes recursos para desarrolladores calificados. Los usuarios de MySQL pueden esperar un rápido desarrollo del software y trabajadores freelance expertos dispuestos a trabajar.
Seguro
Tus datos deberían ser la principal preocupación al elegir el software RDBMS correcto. Con su sistema de privilegios de acceso y la administración de cuentas de usuario, MySQL establece un alto estándar de seguridad. La verificación basada en el host y el cifrado de contraseña están disponibles.
 y fechas y horas")
sudo mysql -u root -> Entrar en MySQL como root ó mysql -u root -h 127.0.0.1 -p y dos veces ENTER
Tipos de datos en MySQL
Datos numéricos
La diferencia entre uno y otro tipo de dato es simplemente el rango de valores que puede contener.
Dentro de los datos numéricos, podemos distinguir dos grandes ramas: enteros y decimales.
Es muy conveniente elegir bien el tipo, ya que dependera del peso de la base, si cojemos uno muy superior ocupara mas espacio en el almacenamiento.
Numéricos enteros
Comencemos por conocer las opciones que tenemos para almacenar datos que sean númericos enteros (edades, cantidades, magnitudes sin decimales); poseemos una variedad de opciones:
| Tipos de datos | Bytes | Valor mínimo | Valor máximo |
|---|---|---|---|
| TINYINT | 1 | -128 | 127 |
| SMALLINT | 2 | -32768 | 32767 |
| MEDIUMINT | 3 | -8388608 | 8388607 |
| INT o INTEGER | 4 | -2147483648 | 2147483647 |
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
Números con decimales
Dejemos los enteros y pasemos ahora a analizar los valores numéricos con decimales.
Estos tipos de datos son necesarios para almacenar precios, salarios, importes de cuentas bancarias, etc. que no son enteros.
Tenemos que tener en cuenta que si bien estos tipos de datos se llaman «de coma flotante«, por ser la coma el separador entre la parte entera y la parte decimal, en realidad MySQL los almacena usando un punto como separador.
En esta categoría, disponemos de tres tipos de datos: FLOAT, DOUBLE y DECIMAL.
La estructura con la que podemos declarar un campo FLOAT implica definir dos valores: la longitud total (incluyendo los decimales y la coma), y cuántos de estos dígitos son la parte decimal. Por ejemplo:
FLOAT (6.2)
Esta definición permitirá almacenar como minimo el valor -999.99 y como máximo 999.99 (el signo menos no cuenta, pero el punto decimal sí, por eso son seis digitos en total, y de ellos dos son los decimales).

La cantidad de decimales (el segundo número entre los paréntesis) debe estar entre 0 y 24, ya que ése es el rango de precisión simple.
En cambio, en el tipo de dato DOUBLE, al ser de doble precisión, sólo permite que la cantidad de decimales se defina entre 25 y 53.
Debido a que los cálculos entre campos en MySQL se realizan con doble precisión (la utilizada por DOUBLE) usar FLOAT, que es de simple precisión, puede traer problemas de redondeo y pérdida de los decimales restantes.
Por último, DECIMAL es ideal para almacenar valores monetarios, donde se requiera menor longitud, pero la «máxima exactitud» (sin redondeos).
Este tipo de dato le asigna un ancho fijo a la cifra que almacenará.
El máximo de dígitos totales para este tipo de dato es de 64, de los cuales 30 es el número de decimales máximo permitido. Más que suficientes para almacenar precios, salarios y monedas.
El formato en el que se definen en el phpMyAdmin es idéntico para los tres: primero la longitud total, luego, una coma y, por ultimo, la cantidad de decimales.
Datos alfanuméricos
Para almacenar datos alfanuméricos (cadenas de caracteres) en MySQL poseemos los siguientes tipos de datos:
- CHAR
- VARCHAR
- BINARY
- VARBINARY
- TINYBLOB
- TINYTEXT
- BLOB
- TEXT
- MEDIUMBLOB
- MEDIUMTEXT
- LONGBLOB
- LONGTEX
- ENUM
- SET
Veremos ahora cuáles son sus caracteristicas y cuáles son las ventajas de usar uno u otro, según qué datos necesitemos almacenar.
CHAR
Comencemos por el tipo de dato alfanumérico mas simple: CHAR (character, o caracter).
Este tipo de dato permite almacenar textos breves, de hasta 255 caracteres de longitud como máximo en caracteres que le definamos, aunque no lo utilicemos.
Por ejemplo, si definieramos un campo «nombre» de 14 caracteres como CHAR, reservará (y consumirá en disco) este espacio.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| J | u | a | n | P | e | r | e | z | |||||
| C | a | r | l | o | s | G | a | r | c | i | a | ||
| J | o | s | e | R | a | m | i | r | e | z | |||
| L | u | i | s | F | e | r | n | a | n | d | e | z | |
| P | e | p | e | L | o | p | e | z |
Por lo tanto, no es eficiente cuando la longitud del dato que se almacenará en un campo es desconocida a priori (tipicamente, datos ingresados por el usuario en un formulario, como su nombre, domicilio, etc.)
¿En qué casos usarlo, entonces? Cuando el contenido de ese campo será completado por nosotros, programadores, al agregarse un registro y, por lo tanto, estamos seguros de que la longitud siempre será la misma.
Pensemos en un formulario con botones de radio para elegir el «sexo»; independientemente de lo que muestren las etiquetas visibles para el usuario, podríamos almacenar un solo caracter M o F (masculino o femenino) y, en consecuencia, el ancho del campo CHAR podría ser de un digito, y sería suficiente. Lo mismo sucede con códigos que identifiquen provincias, países, estados civiles, etc.
VARCHAR
Completariamente, el tipo de dato VARCHAR (character varying, o caracteres variables) es útil cuando la longitud del dato es desconocida, cuando depende de la información que el usuario escribe en campos o áreas de texto de un formulario.
La longitud máxima permitida era de 255 caracteres hasta MySQL 5.0.3. pero desde esta versión cambio a un máximo de 65.535 caracteres.
Este tipo de dato tiene la partícularidad de que cada registro puede tener una longitud diferente, que dependerá de su contenido; si en su registro el campo «nombre» (supongamos que hubiera sido definido con un ancho máximo de 20 caracteres) contiene solamente el texto: «Pepe», consumirá sólo cinco caracteres, cuatro para las cuatro letras, y uno más que indicará cuántas letras se utilizaron.
Si luego, en otro registro, se ingresa un nombre de 15 caracteres, consumirá 16 caracteres (siempre uno más que la longitud del texto, mientras la longitud no supere los 255 caracteres; si no los supera, serán dos los bytes necesarios para indicar la longitud).
Por lo tanto, será más eficiente para almacenar registros cuyos valores tengan longitudes variables, ya que si bien «gasta» uno o dos caracteres por registro para declarar la longitud, esto le permite ahorrar muchos otros caracteres que no serían utilizados.
En cambio, en el caso de datos de longitud siempre constante, sería un desperdicio gastar un caracter por registro para almacenar la longitud, y por eso convendría utilizar CHAR en esos casos.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| J | u | a | n | P | e | r | e | z | |||||
| C | a | r | l | o | s | G | a | r | c | i | a | ||
| J | o | s | e | R | a | m | i | r | e | z | |||
| l | u | i | s | F | e | r | n | a | n | d | e | z | |
| P | e | p | e | L | o | p | e | z |
BINARY Y VARBINARY
Estos dos tipos de datos son identicos a CHAR y VARCHAR, respectivamente, salvo que almacenan bytes en lugar de caracteres, una diferencia muy sutil para un nivel básico a intermedio de MySQL.
TEXT
Antes de la versión 5.0.3. de MySQL, este campo era el utilizado «por excelencia» para descripciones de productos, coméntarios, textos de noticia, y cualquier otro texto largo.
Pero, a parir de la posibilidad de utilizar VARCHAR para longitudes de hasta 65.535 caracteres, es de esperar que se utilice cada vez menos este tipo de campo.
La principal desventaja de TEXT es que no puede indexarse facilmente (a diferencia de VARCHAR).
Tampoco se le puede asignar un valor predeterminado a un campo TEXT (un valor por omisión que se complete automaticamente si no se ha proporcionado un valor al insertar un registro).
Sólo deberíamos utilizarlo para textos realmente muy largos, como los que mencionamos al comienzo de este parrafo.
BLOB
Es un campo que guarda información en formato binario y se utiliza cuando desde PHP se almacena en la base de datos el contenido de un archivo binario (típicamente, una imagen o un archivo comprimido ZIP) leyéndolo byte a byte, y se requiere almacenar todo su contenido para luego reconstruir el archivo y servidor al navegador otra vez, sin necesidad de almacenar la imagen o el ZIP en un disco, sino que sus bytes quedan guardados en un campo de una tabla de la base de datos.
El tamaño máximo que almacena es de 65.535 bytes.
De todos modos, y como lo hemos mencionado en este ejemplo, respecto al tipo de dato para una imagen, usualmente no se guarda «la imagen» (sus bytes, el contenido del archivo) en la base de datos porque, un sitio grande, se vuelve muy pesada y lenta la base de datos, sino que almacena sólo la URL que lleva hasta la imagen.
De esa forma, para mostrar la imagen simplemente se lee ese campo URL y se completa una etiqueta img con esa URL, y esto es suficiente para que el navegador muestre la imagen. Entonces, con un VARCHAR alcanza para almacenar la URL de una imagen.
El campo BLOB es para almacenar directamente «la imagen» (o un archivo comprimido, o cualquier otro archivo binario), no su ruta.
TINYBLOB, MEDIUMBLOB Y LONGBLOB
Similares al BLOB, sólo cambia la longitud máxima:
- TINYBLOB es de 255 bytes
- MEDIUMBLOB es de 16.777.215 bytes, y
- LONGBLOB es de 4 Gb (o lo máximo que permita manipular el sistema operativo).
ENUM
Su nombre es la abreviatura de «enumeración«. Este campo nos permite establecer cuáles serán los valores posibles que se le podrán insertar.
Es decir, crearemos una lista de valores permitidos, y no se autorizará el ingreso de ningún valor fuera de la lista, y se permitirá elegir solo uno de estos datos como valor del campo.
Los valores deben estar separados por comas y envueltos entre comillas simples.
El máximo de valores diferentes es de 65.535.
Lo que se almacenará no es la cadena de caracteres en sí, sino el número de índice de su posición dentro de la enumeración.
Por ejemplo, si al crear la tabla definimos un campo de esta manera:

En este ejemplo, la categoría será excluyente, no podremos elegir más de una, y todo docente (uno por registro) deberá tener una categoría asignada.
SET
Su nombre significa «conjunto«. De la misma manera que ENUM, debemos especificar una lista, pero de hasta 64 opciones solamente.
La carga de esos valores es idéntica a la de ENUM, una lista de valores entre comillas simples, separados por comas. Pero, a diferencia de ENUM, sí podemos llegar a dejarlo vacío, sin elegir ninguna opción de las posibles.
Y también podemos elegir como valor del campo más de uno de los valores de la lista.
Por ejemplo, darnos a elegir una serie de temas (típicamente con casillas de verificación que permiten selección múltiple) y luego almacenamos en un solo campo todas las opciones elegidas.
Un detalle importante es que cada valor dentro de la cadena de caracteres no puede contener comas, ya que es la coma el separador entre un valor y otro.

Unas vez definido este tipo de dato, podemos cargar valores múltiples para ese campo dentro de un mismo registro, pulsando » Control» mientras hacemos clic en cada opción.
Eso significará, en este ejemplo de una tabla de alumnos, que ese alumno está cursando ambas materias seleccionadas.

Si una vez agregado algún registro pulsamos en «Examinar» para ver el contenido de la tabla, veremos que este registro, que en un campo contenía un valor múltiple, incluye lo siguiente:

Con esto damos por finalizado el grupo de tipos de datos alfanuméricos. Pasemos ahora al último grupo, el de fechas y horas.
Datos de fecha y hora
En MySQL, poseemos varias opciones para almacenar datos referidos a fechas y horas.
Veamos las diferencias entre uno y otro, y sus usos principales, así podemos elegir el tipo de dato apropiado en cada caso.
DATE
El tipo de dato DATE nos permite almacenar fechas en el formato: AAAA-MM-DD (los cuatro primeros dígitos para el año, los dos siguientes para el mes, y los ultimos dos para el dia).
Atención:
En los países de habla hispana estamos acostumbrados a ordenar las fechas en Día, Mes y Año, pero para MySQL es exactamente al revés.
Tengamos en cuenta que esto nos obligará a realizar algunas maniobras de reordenamiento utilizando funciones de manejo de caracteres.
Si bien al leer un campo DATE siempre nos entrega los datos separados por guiones, al momento de insetar un dato nos permite hacerlo tanto en formato de número continuo (por ejemplo, 201512319, como utilizando cualquier caracter separador (2015-12-31 o cualquier otro caracter que separe los tres grupos).
El rango de fechas que permite manejar desde el 1000-01-01 hasta el 9999-12-31.
Es decir, que no nos será útil si trabajamos con una línea de tiempo que se remote antes del año 1000, (¿alguna aplicación relacionada con la historia?), pero si nos resultara útil para datos de un pasado cercano y un futuro muy largo por delante, ya que llega casi hasta el año 10.000.
DATETIME
Un campo definido como DATETIME nos permitirá almacenar información acerca de un instante de tiempo, pero no sólo la fecha sino también su horario, en el formato:
AAAA-MM-DD HH:MM:SS
Siendo la parte de la fecha de un rango similar al del tipo DATE (desde el 1000-01-01 00:00:00 al 9999-12-31 23:59:59), y la parte del horario, de 00:00:00 a 23:59:59.
TIME
Este tipo de cambio permite almacenar horas, minutos y segundos, en el formato HH:MM:SS, y su rango permitido va desde –839:59:59 hasta 839:59:59 (unos 35 días hacia atrás y hacia adelante de la fecha actual). Esto lo hace ideal para calcular tiempos trancurridos entre dos momentos cercanos.
TIMESTAMP
Un campo que tenga definido el tipo de dato TIMESTAMP sirve para almacenar una fecha y un horario, de manera similar a DATETIME, pero su formato y rango de valores serán diferentes.
El fomato de un campo TIMESTAMP puede variar entre tres opciones:
- AAAA-MM-DD HH:MM:SS
- AAAA-MM-DD
- AA-MM-DD
Es decir, la longitud posible puede ser de 14, 8 o 6 dígitos, según qué información proporcionemos.
El rango de fechas que maneja este campo va desde el 1970-01-01 hasta el año 2037.
Además, posee la particularidad de que podemos definir que su valor se mantenga actualizado automáticamente,cada vez que se inserte o que se actualice un registro.
De esa manera, conservaremos siempre en ese campo la fecha y hora de la última actualización de ese dato, que es ideal para llevar el control sin necesidad de programar nada.
Para definir esto desde el phpMyAdmin, deberemos seleccionar en Atributos la opción «on update» CURRENT_TIMESTAMP, y como valor predeterminado CURRENT_TIMESTAMP:

Campo cuyo valor se actualizará automáticamente al insertar o modificar un registro
YEAR
En caso de definir un campo como YEAR, podremos almacenar un año, tanto utilizando dos como cuatro dígitos.
En caso de hacerlo en dos dígitos, el rango posible se extenderá desde 70 hasta 99 (del 70 hasta el 99 se entenderá que corresponden al rango de años entre 1970 y 1999, y del 00 al 69 se entenderá que se refiere a los años 2000 a 2069); en caso de proporcionar los cuatro digitos, el rango posible se ampliará, yendo desde 1901 hasta 2155.
Una posibilidad extra, ajena a MySQL pero relativa a las fechas y horarios, es generar un valor de timestamp con la función time de PHP (repito, no estamos hablando de MySQL, no nos confundamos a causa de tantos nombres similares).
A ese valor, lo podemos almacenar en un campo INT de 10 dígitos.
De esa forma, será muy simple ordenar los valores de ese campo (supongamos que es la fecha de una noticia) y luego podremos mostrar la fecha transformando ese valor de timestamp en algo legible mediante funciones de manejo de fecha propias de PHP.
Atributos de los campos
Ya hemos visto los diferentes tipos de datos que es posible utilizar al definir un campo en una tabla, pero estos tipos de datos pueden poseer ciertos modificadores o «atributos» que se pueden especificar al crear el campo, y que nos brindan la posibilidad de controlar con mayor exactitud qué se podrá almacenar en ese campo, cómo lo almacenaremos y otros detalles.
Aunque algunos de estos atributos ya los hemos utilizado intuitivamente al pasar en algunos de los ejemplos anteriores, a continuación vamos a analizar más en detalle.
¿Null o Not Null?
Algunas veces tendremos la necesidad de tener que agregar registros sin que los valores de todos sus campos sean completados, es decir, dejando algunos campos vacíos (al menos provisoriamente).
Por ejemplo, en un sistema de comercio electrónico, podría ser que el precio, o la descripción completa de un producto, o la cantidad de unidades en depósito, o la imagen del producto, no estén disponibles en el momento en que, como programadores, comencemos a trabajar con la base de datos.
Todos esos campos, nos conviene que sean definidos como NULL (nulos), para que podamos ir agregando registros con los datos básicos de los productos (su nombre, código, etc.) aunque todavía la gente del área comercial no haya definido el precio, ni el área de marketing haya terminado las descripciones, ni los diseñadores hayan subido las fotos (es típica esta división de tareas en empresas grandes, y hay que tenerla presente, porque afecta la declaración de campos de nuestras tablas).
Si definimos esos campos que no son imprescindibles de llenar de entrada como NULL (simplemente marcando la casilla de verificación a la altura de la columna NULL, en el phpMyAdmin), el campo queda preparado para que, si no es que proporcionado un valor, quede vacío pero igual nos permita completar la inserción de un registro completo.
Por omisión, si no marcamos ninguna casilla, todos los campos son NOT NULL, es decir, es obligatorio ingresar algún valor en cada campo para poder cargar un nuevo registro en la tabla.
Valor predeterminado (default)
Muchas veces necesitamos agilizar la carga de datos mediante un valor por defecto (default).
Por ejemplo, pensemos en un sistema de pedidos, donde, al llegar el pedido a la base de datos, su estado sea «recibido», sin necesidad de que el sistema envíe ningún valor, sólo por agregar el registro, ese registro debería contener en el campo «estado» el valor de «recibido».
Este es un típico caso de valor predeterminado o por default.
En phpMyAdmin, podemos especificar que un campo tenga un valor predeterminado de tres maneras posibles:
Escribiendo nosotros a mano el valor (como en el caso de «recibido») en cuyo caso debemos elegir la primera de las opciones de la columna «Predeterminado», la que dice «Como fuera definido:», y debemos escribir el valor en el campo de texto existente justo debajo de ese menú:

- Podemos definir que el valor por omisión sea NULL, es decir, que si no se proporciona un valor, quede el valor NULL como valor de ese campo.
- Y, por último, podemos definir para un campo de tipo TIMESTAMP que se inserte como valor por defecto el valor actual de TIMESTAMP (Current_Timestamp), algo que hemos visto en detalle al referirnos a este tipo de dato.
En los dos casos, debemos dejar vacío el cuadro de texto inferior.
Es importante señalar que no se puede dar un valor predeterminado a un campo de tipo TEXT ni BLOB (y todas sus variantes).
Ordenamiento binario
Definir un campo de texto CHAR o VARCHAR como BINARY (binario) sólo afecta en el ordenamiento de los datos: en vez de ser indiferentes a mayúsculas y minúsculas, un campo BINARY se ordenará teniendo en cuenta esta diferencia, por lo cual, a igualdad de letra, primero aparecerán los datos que contengan esa letra en mayúsculas.
Se define desde el phpMyAdmin eligiendo BINARY en el menú Atributos:

Índices
El objetivo de crear un índice es mantener ordenados los registros por aquellos campos que sean frecuentemente utilizados en búsquedas, para así agilizar los tiempos de respuesta.
Un índice no es más que una tabla «paralela», que guarda los mismos datos que la tabla original, pero en vez de estar ordenados por orden de inserción o por la clave primaria de la tabla, en el índice se ordenan por el campo que elegimos indexar.
Por ejemplo, si hubiera un buscador por título de noticia, en la tabla de noticias le asignaríamos un índice al campo «título», y las noticias estarían ordenadas de la «a» a la «z» por su título.
La búsqueda se realizará primero en el índice, encontrando rápidamente el título buscado, ya que están todos ordenados y, como resultado, el índice le devolverá al programa MySQL el identificador (id) del registro en la tabla original, para que MySQL vaya directamente a buscar ese registro con el resto de los datos, sin perder tiempo.
Todo esto, por supuesto, de manera completamente invisible para nosotros.
Para indicar que queremos crear un índice ordenado por un campo determinado, al campo que se indexará debemos especificarle, dentro del atributo Índice, del menú de selección que aparece a su derecha, la opción Index:

Como podemos apreciar, dentro del menú Índice que aparecen otras opciones: Primary, Unique y Fulltext. Veamos en qué consiste cada una de estas variantes.
PRIMARY Key y Auto_Increment
Siempre, en toda la tabla, uno de los campos (por convención, el primero, y también por convención usualmente llamado id –por «identificador»-), debe ser de definido como clave primario o Primary Key.
Esto impedirá que se le inserten valores repetidos y que se deje nulo su valor.
Habitualmente, se especifica que el campo elegido para clave primaria sea numérico, de tipo entero (en cualquiera de sus variantes, según la cantidad de elementos que se identificarán) y se le asigna otro atributo típico, que es Auto_Increment, es decir, que no nos preocupamos por darle valor a ese campo: al agregar un registro, MySQL se ocupa de incrementar en uno el valor de la clave primaria del último registro agregado, y se lo asigna al nuevo registro.
Este campo no suele tener ninguna relación con el contenido de la tabla, su objetivo es simplemente identificar cada registro de forma única, irrepetible.

Podemos definir un sólo campo como clave primaria, o dos o más campos combinados.
En caso de haber definido dos o más campos para que juntos formen el valor único de una clave primaria, diremos que se trata de una clave primaria «combinada» o «compuesta«.
UNIQUE
Si especificamos que el valor de un campo sea Unique, estaremos obligando a que su valor no pueda repetirse en más de un registro, pero no por eso el campo se considerará clave primaria de cada registro.
Esto es útil para un campo que guarde, por ejemplo, número de documentos de identidad, la casilla de correo electrónico usada para identificar el acceso de un usuario, un nombre de usuario, o cualquier otro dato que no debamos permitir que se repita.
Los intentos por agregar un nuevo registro que contenga un valor ya existente en ese campo, serán rechazados.
FULLTEXT
Si en un campo de tipo TEXT creamos un índice de tipo FULLTEXT, MySQL examinará el contenido de este campo palabra por palabra, almacenando cada palabra en una celda de una matriz, permitiendo hacer búsquedas de palabras contenidas dentro del campo, y no ya una simple búsqueda de coincidencia total del valor del campo, que son mucho más rápidas pero no sirven en el caso de búsqueda dentro de, por ejemplo, el cuerpo de una noticia, donde el usuario desea encontrar noticias que mencionan determinada palabra.
Se ignoran las palabras de menos de cuatro caracteres y palabras comunes como artículos, etc. que se consideran irrelevantes para una búsqueda, así como también se iganoran diferencias entre mayúsculas y miniscúlas.
Además, si la palabra buscada se encuentra en más de 50% de los registros, no devolverá resultados, ya que se la considera irrelevante por «exceso» de aparición (deberemos refinar la búsqueda en este caso).
Con esto, damos por terminada esta revisión bastante exhaustiva.
Ya hemos aprendido a crear una base de datos y una tabla, definiendo con total precisión sus campos valiéndolos de tipos de datos y atributos, por lo tanto, estamos en condiciones de comenzar a programar todo lo necesario para que nuestras páginas PHP se conecten con una base de datos y puedan enviarle o le soliciten datos.
A continuación os mostramos los tipos de datos (data types) que se pueden definir para el motor de base de datos MySQL:
| Grupo | Tipo de dato | Intervalo | Almacenamiento |
| Numéricos | TINYINT |
De -128 a 127 (signed) |
1 byte |
| SMALLINT |
De -32768 a 32767 (signed) |
2 bytes | |
| MEDIUMINT |
De -8388608 a 8388607 (signed) |
3 bytes | |
| INT INTEGER |
De -2147483648 a 2147483647 (signed) |
4 bytes | |
| BIGINT | De -9223372036854775808 a 9223372036854775807 (signed) De 0 a 18446744073709551615 (unsigned) |
8 bytes | |
| BIT | Equivalente a TINYINT(1) | 1 byte | |
| BOOL BOOLEAN |
Equivalente a TINYINT(1) Valor 0 = False Valor 1 = True |
1 byte | |
| FLOAT [(M,D)] |
De -3.402823466E+38 a -1.175494351E-38, 0, y desde 1.175494351E-38 a 3.402823466E+38 M es el número total de dígitos y D es el número de dígitos después del punto decimal. Si se omite M y D, los valores se almacenan en los límites permitidos por el hardware (unas 7 posiciones decimales) |
4 bytes | |
| FLOAT (p) |
p representa la precisión en bits, MySQL usa este valor sólo para determinar si se debe usar FLOAT o DOUBLE para el tipo de datos resultante. Si p está entre 0 a 24, el tipo de datos se convierte en FLOAT (sin M ó D). Si p está entre 25 a 53, el tipo de datos se convierte a DOUBLE (sin M ó D). En realidad este tipo de datos es proporcionado por MySQL por compatibilidad con ODBC |
4 bytes si 0 <= p <= 24, 8 bytes si 25 <= p <= 53 | |
| DOUBLE [(M,D)] |
De -1.7976931348623157E+308 a -2.2250738585072014E-308, 0, y desde 2.2250738585072014E-308 a 1.7976931348623157E+308 M es el número total de dígitos y D es el número de dígitos después del punto decimal. Si se omite M y D, los valores se almacenan en los límites permitidos por el hardware (unas 15 posiciones decimales) |
8 bytes | |
| REAL[(M,D)] DOUBLE PRECISION |
Equivalente a DOUBLE, con la excepción de que si está activado el modo REAL_AS_FLOAT, REAL es un sinónimo de FLOAT en lugar de DOUBLE | 4 Bytes ó 8 bytes | |
| DECIMAL [(M[,D])] DEC [(M[,D])] NUMERIC [(M[,D])] FIXED[(M[,D])] |
Número en coma flotante sin empaquetar. Se comporta como una columna CHAR. El número se almacena como una cadena, usando un carácter para cada dígito del valor. El rango máximo es el mismo que para el tipo DOUBLE |
M+2 bytes sí D > 0 |
|
| Fecha y hora | DATE | Fecha, con rango desde ‘1000-01-01’ a ‘9999-12-31’ con formato ‘YYYY-MM-DD’ | 3 bytes |
| DATETIME | Fecha y hora, con rango desde ‘1000-01-01 00:00:00’ a ‘9999-12-31 23:59:59’ con formato ‘YYYY-MM-DD HH:MM:SS’ | 8 bytes | |
| TIMESTAMP[(M)] | Fecha y hora, el rango va desde ‘1970-01-01 00:00:01’ UTC a ‘2038-01-19 03:14:07’ UTC. El formato de almacenamiento depende del tamaño del campo | 4 bytes | |
| TIME | Hora, con rango desde ‘-838:59:59’ a ‘838:59:59’, con el formato ‘HH:MM:SS’ | 3 bytes | |
| YEAR[(2|4)] | Año en dos o cuatro dígitos, para cuatro dígitos, el rango es de 1901 a 2155, para dos dígitos es de 70 a 69 (representando desde 1070 a 2069) | 1 byte | |
| Cadenas de caracteres | CHAR (M) | Almacena una cadena de longitud fija. La cadena podrá contener desde 0 a 255 caracteres | M bytes (tanto si se ocupan como si no) |
| VARCHAR (M) | Almacena una cadena de longitud variable. La cadena podrá contener desde 0 a 255 caracteres | Tamaño contenido del campo más 1 byte | |
| BINARY (M) | Similar a CHAR, excepto que contiene cadenas de caracteres binarias en lugar de cadenas no binarias. Es decir, que contienen cadenas de bytes en lugar de cadenas de caracteres. Esto significa que no tienen conjunto de caracteres, y la comparación y ordenación se basa en los valores numéricos de los bytes en los valores | M bytes, 0 <= M <= 255 | |
| VARBINARY (M) | Similar a VARCHAR, excepto que contiene cadenas de caracteres binarias en lugar de cadenas no binarias. Es decir, que contienen cadenas de bytes en lugar de cadenas de caracteres. Esto significa que no tienen conjunto de caracteres, y la comparación y ordenación se basa en los valores numéricos de los bytes en los valores | Tamaño contenido del campo más 1 byte | |
| TEXT | Tipo de datos no binario que puede contener una cantidad variable de datos. Sirve para almacenar texto (gran cantidad). Hasta 65535 caracteres | Longitud + 2 bytes, mientras L < 216 | |
| TINYTEX | Tipo de datos no binario que puede contener una cantidad variable de datos. Sirve para almacenar texto (gran cantidad). Hasta 255 caracteres | Longitud + 1 bytes, mientras L < 28 | |
| MEDIUMTEXT | Tipo de datos no binario que puede contener una cantidad variable de datos. Sirve para almacenar texto (gran cantidad). Hasta 16.777.215 caracteres | Longitud + 3 bytes, mientras L < 224 | |
| LONGTEXT | Tipo de datos no binario que puede contener una cantidad variable de datos. Sirve para almacenar texto (gran cantidad). Hasta 4.294.967.295 caracteres | Longitud + 4 bytes, mientras L < 232 | |
| BLOB | Tipo de datos binario que puede contener una cantidad variable de datos. Permite almacenar ficheros (de cualquier tipo). Hasta 65535 bytes | Longitud + 2 bytes, mientras L < 216 | |
| TINYBLOB | Tipo de datos binario que puede contener una cantidad variable de datos. Permite almacenar ficheros (de cualquier tipo). Hasta 255 bytes | Longitud + 1 bytes, mientras L < 28 | |
| MEDIUMBLOB | Tipo de datos binario que puede contener una cantidad variable de datos. Permite almacenar ficheros (de cualquier tipo). Hasta 16.777.215 bytes | Longitud + 3 bytes, mientras L < 224 | |
| LONGBLOB |
Tipo de datos binario que puede contener una cantidad variable de datos. Permite almacenar ficheros (de cualquier tipo). Hasta 4.294.967.295 bytes |
Longitud + 4 bytes, mientras L < 232 | |
| ENUM (valor1, valor2, …) | Es un tipo de datos de cadena con un valor elegido de una lista de valores permitidos que se enumeran explícitamente en la especificación de la columna al crear la tabla. Acepta hasta 65535 valores distintos | 1 ó 2 bytes, dependiendo del número de valores de ENUM | |
| SET (valor1, valor2, …) | Es un tipo de datos de cadena que puede contener ninguno, uno ó varios valores de una lista previamente establecida (al crear la tabla). La lista puede tener un máximo de 64 valores | 1, 2, 3, 4, ó 8 bytes, dependiendo del número de miembros del conjunto | |
| Tipos de datos espaciales (Open Gis) (*) | GEOMETRY | Geometry es la clase base de la jerarquía para el modelo geométrico OpenGIS. Es una clase no instanciable, pero tiene unas cuantas propiedades que son comunes para todos los valores geométricos creados con cualquiera de las subclases de Geometry | |
| POINT | Un POINT es una geometría que representa una ubicación única en un espacio de coordenadas (valor de la coordenada X, valor de la coordenada Y) | ||
| LINESTRING | Un LINESTRING es una Curva con interpolación linear entre puntos. Un LINESTRING tiene coordenadas de segmentos, definidos por cada par consecutivo de puntos | ||
| POLYGON | Un POLYGON es una superficie planar que representa una geometría multicara. Se define por un único límite exterior y cero o más límites interiores, donde cada límite interior define un agujero en el polígono | ||
| MULTIPOINT | Un MULTIPOINT es una colección de geometrías compuesta de elementos Point. Los puntos no están conectados ni ordenados de ningún modo | ||
| MULTILINESTRING | Una MULTILINESTRING es una colección de geometrías MultiCurve compuesta de elementos LINESTRING | ||
| MULTIPOLYGON | Un MULTIPOLYGON es un objeto MultiSurface compuesto de elementos POLYGON | ||
| GEOMETRYCOLLECTION |
Una GEOMETRYCOLLECTION es una geometría que consiste en una colección de una o más geometrías de cualquier clase. Todos los elementos en una GEOMETRYCOLLECTION deben estar en el mismo Sistema de Referencia Espacial (es decir, en el mismo sistema de coordenadas) |
||
| CURVE | Una clase CURVE es una geometría unidimensional, normalmente representada por una secuencia de puntos. Las subclases particulares de CURVE definen el tipo de interpolación entre puntos. CURVE es una clase no instanciable | ||
| MULTICURVE | Una clase MULTICURVE es una colección de geometrías que se compone de elementos CURVE. MULTICURVE es una clase no instanciable | ||
| SURFACE | Una clase SURFACE es una geometría bidimensional. Es una clase no instanciable. Su única subclase instanciable es POLYGON |
(*) MySQL implementa extensiones espaciales siguiendo la especificación del Consorcio Open GIS (OGC), un consorcio internacional de más de 250 compañías, agencias y universidades que participan en el desarrollo de soluciones conceptuales públicamente disponibles y que pueden ser útiles para todo tipo de aplicaciones que manejan datos espaciales. MySQL implementa un subconjunto del entorno SQL con Tipos Geométricos propuesto por el OGC. Este término se refiere a un entorno SQL que ha sido extendido con un conjunto de tipos geométricos. Una columna SQL con valores geométricos se implementa como una columna que tiene un tipo geométrico. Las especificaciones describen un conjunto de tipos geométricos SQL, así como las funciones para analizar y crear valores geométricos sobre esos tipos.